NVIDIA เผยแพร่งานวิจัย Video-to-Video Synthesis หรือ vid2vid โครงการสังเคราะห์วิดีโอในรูปแบบต่างๆ โดยมีความเหนือกว่าโมเดลเดิมๆ คือสามารถสร้างวิดีโอความละเอียดสูงระดับ 2K (2018x1024)
นักวิจัยลองฝึกโมเดลด้วยชุดข้อมูลต่างๆ เช่น ชุดข้อมูล Cityscape มาจัดส่วนต่างๆ ของภาพ (segmentation) ด้วย Mask R-CNN แล้วฝึกให้โมเดลสร้างวิดีโอจากภาพ segmentation ผลที่ได้คือวิดีโอที่สามารถแปลงสภาพแวดล้อม จากพื้นถนนปูนให้เป็นพื้นอิฐ หรือแปลงสภาพแวดล้อมจากต้นไม้ให้เหลือแต่ตึก
อีกการทดลองหนึ่งอาศัยวิดีโอเต้นโคฟเวอร์จาก YouTube แล้วแปลงวิดีโอเป็นท่าทางของคนเต้น (pose) ด้วยโมเดล DensePose และ OpenPose จากนั้นฝึกกลับให้สร้างวิดีโอจากท่าเต้น นักวิจัยพบว่าโมเดลสามารถสร้างท่าเต้นได้สมจริง แม้จะพบท่าเต้นที่ไม่เคยเจอมาก่อนในชุดข้อมูลฝึก ตัวอย่างวิดีโอที่สร้างจากคนเต้นจริง (วิดีโอตัวอย่าง แสดงวิดีโอต้นฉบับอันซ้าย และวิดีโอที่สร้างขึ้นอีกสองอัน)
ทีมวิจัยฝึกโมเดลด้วยการ์ดกราฟิก 8 ใบโดยแต่ละใบมีแรม 24GB ซอฟต์แวร์ใช้ PyTorch 0.4
ที่มา - GitHub: NVIDIA/vid2vid, ArXiV
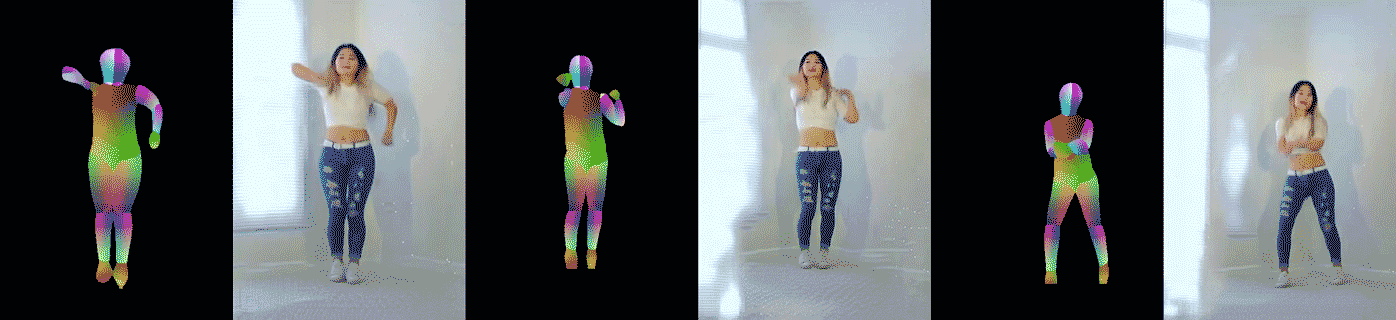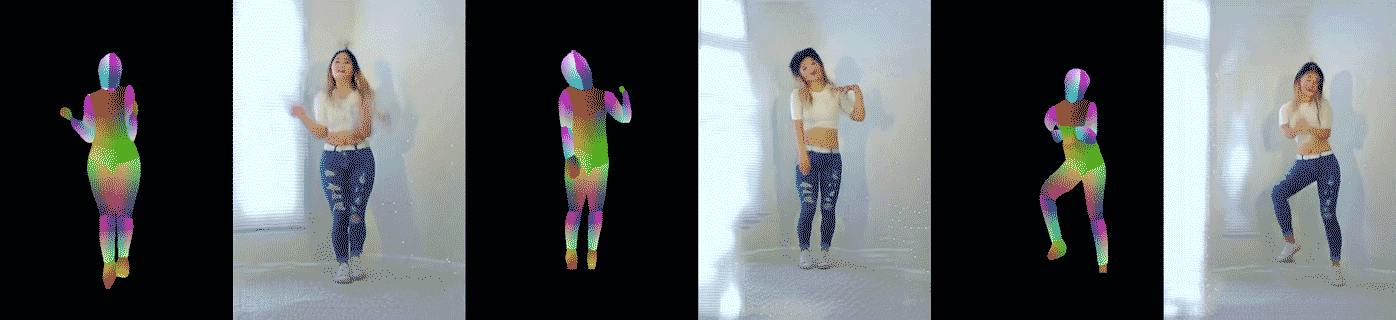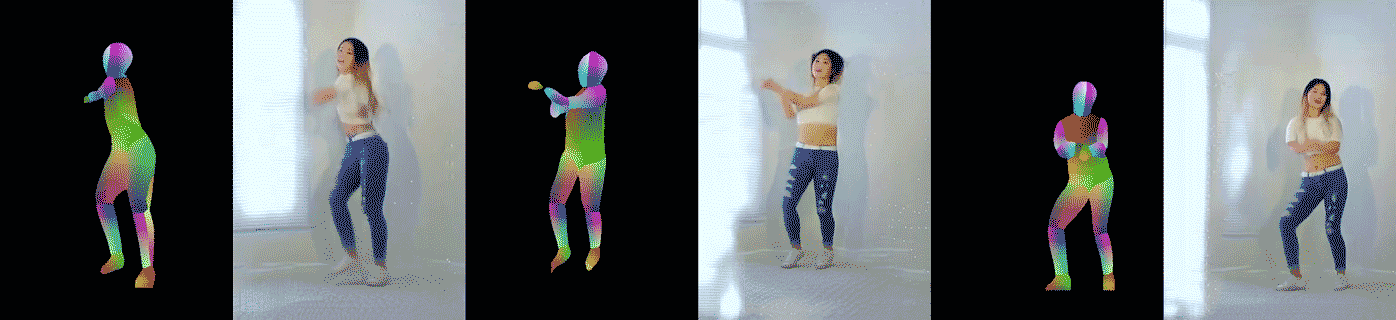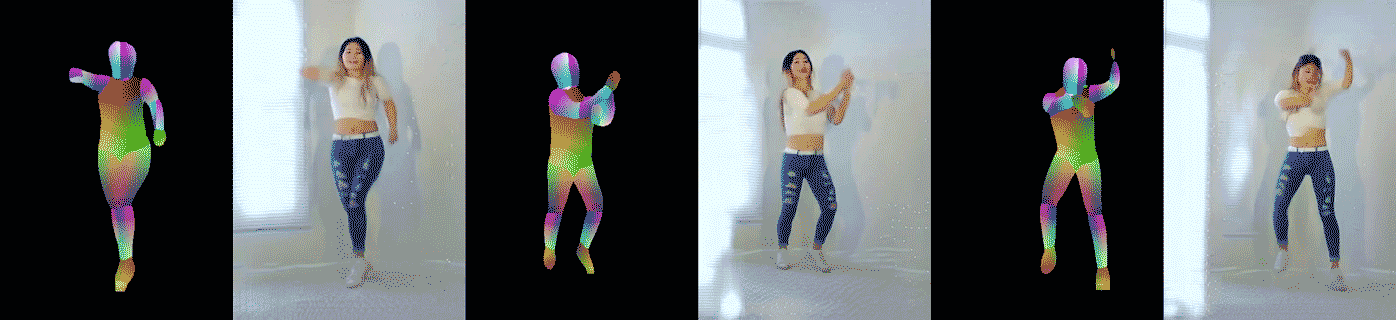{kind=link}