กูเกิลอธิบายสถาปัตยกรรมฟีเจอร์ Live Caption ใน Pixel 4 ใช้โมเดล deep learning 3 ชุดแบ่งหน้าที่กัน



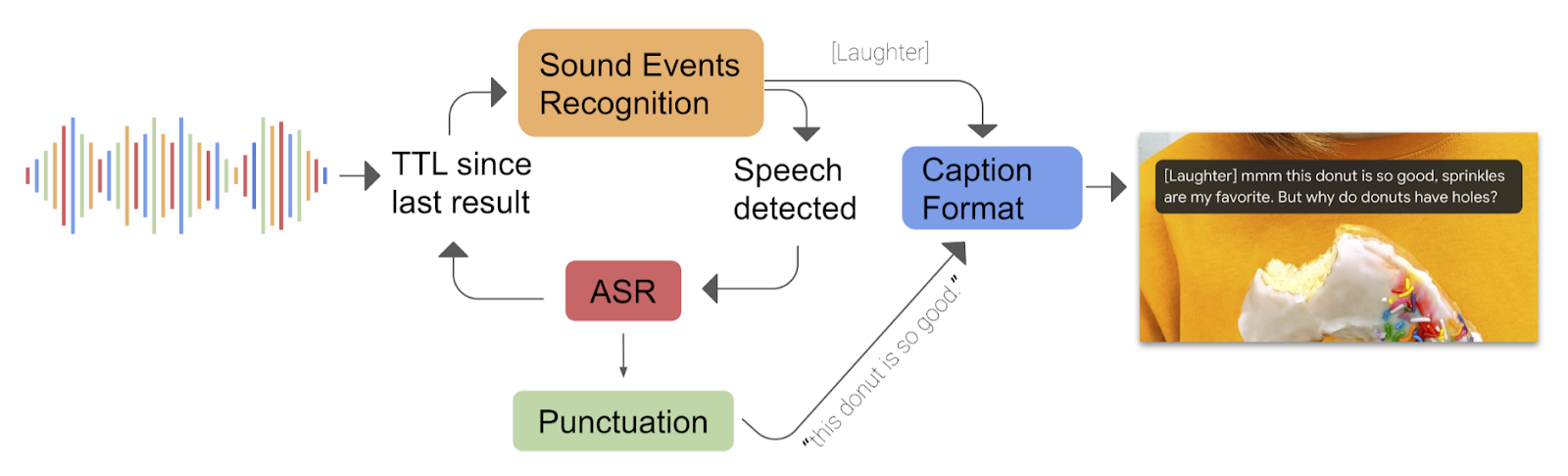
กูเกิลอธิบายถึงสถาปัตยกรรมของการใช้ deep learning ในฟีเจอร์ Live Caption ที่เป็นการทำคำบรรยายเสียงในจากโทรศัพท์ทั้งหมด โดยใช้โมเดล deep learning ทำหน้าที่ต่างกันถึง 3 ชุดในฟีเจอร์นี้
โมเดลแรกที่รันอยู่ตลอดเวลาที่ฟีเจอร์ทำงานคือโมเดลจัดหมวดหมู่เสียง (sound event recognition) โดยภายในเป็นโมเดลแบบ convolutional neural network (CNN) ทำหน้าที่จัดหมวดหมู่ว่าเสียงตอนนี้เป็นเหตุการณ์แบบใด เช่น เสียงหัวเราะ, เสียงดนตรี, หรือเป็นเสียงพูด
เมื่อพบเสียงพูด เสียงส่วนที่เป็นคำพูดจะส่งต่อไปยังโมเดลแปลงเสียงเป็นคำพูดที่สถาปัตยกรรมภายในเป็นแบบ recurrent neural network transducers (RNN-T) โดยโมเดลนี้จะทำงานเฉพาะเมื่อพบเสียงพูดเท่านั้นเพื่อประหยัดหน่วยความจำและพลังงาน โดยโมเดลนี้ย่อมาจากโมเดลเต็มด้วยเทคนิคต่างๆ เช่น การลดความเชื่อมโยงในโมเดล (neural connection pruning) ทำให้โมเดลมีขนาดลดลงครึ่งหนึ่งแต่ยังได้ประสิทธิภาพที่ดี
โมเดลสุดท้ายคือตัวใส่เครื่องหมายเว้นวรรค (punctuation) เพื่อสร้างรูปประโยคให้สมบูรณ์
ฟีเจอร์นี้เริ่มใช้งานได้แล้วใน Pixel 4 และรองรับเฉพาะภาษาอังกฤษ ส่วน Pixel 3 จะได้รับในปีนี้ และทีมงานเตรียมรองรับภาษาอื่นๆ ตลอดจนฟีเจอร์เพิ่มเติมเช่นการพูดหลายคน
ที่มา - Google AI Blog