กูเกิลปล่อยชุดข้อมูลภาพเอกซเรย์ปอดกว่าห้าแสนภาพ เปิดทางสร้างปัญญาประดิษฐ์วิเคราะห์โรคประสิทธิภาพสูง



กูเกิลร่วมกับโรงพยาบาล Apolllo สร้างชุดข้อมูลภาพเอกซเรย์พร้อมป้ายกำกับ โดยภาพจากทางโรงพยาบาลอยู่ในบันทึกการรักษาที่ไม่ได้ติดป้ายกำกับพร้อมสำหรับการใช้ฝึกปัญญาประดิษฐ์
แนวทางของกูเกิลคือการใช้ปัญญาประดิษฐ์อ่านข้อความไปอ่านบันทึกการรักษาเพื่อสร้างป้ายกำกับภาพเอกซเรย์ปอดอีกที กระบวนการนี้ทำให้ได้ภาพพร้อมป้ายกำกับถึง 560,000 ภาพ จากนั้นนำภาพบางส่วนให้รังสีแพทย์มาตรวจสอบอีกครั้งเพื่อให้แน่ใจว่าคุณภาพชุดข้อมูลดีพอ
หลังจากได้ชุดข้อมูลขนาดใหญ่สำหรับฝึกปัญญาประดิษฐ์แล้ว กูเกิลยังสร้างชุดข้อมูลทดสอบคุณภาพสูง โดยอาศัยรังสีแพทย์ตั้งเป็นกรรมการ 3 คนเพื่อพิจารณาภาพเอกซเรย์ทีละภาพ หากความเห็นตรงกันก็จะถือใช้ข้อมูลป้ายกำกับจากกรรมการ หากความเห็นไม่ตรงกันจะส่งให้กรรมการชุดต่อไปพิจารณาใหม่ ไม่เกิน 5 รอบ โดยรอบสุดท้ายหากความเห็นไม่ตรงกันจะถือเสียงส่วนใหญ่ กระบวนการนี้น่าจะทำให้ได้ชุดข้อมูลคุณภาพสูงมากสำหรับการวัดประสิทธิภาพปัญญาประดิษฐ์ต่อไป
กูเกิลระบุว่ารูปแบบของชุดข้อมูลก็มีส่วนสำคัญ เช่นการตรวจภาวะปอดรั่ว (pneumothorax) ของรังสีแพทย์นั้นมีความแม่นยำประมาณ 79% เมื่อดูชุดข้อมูล ChestX-ray14 แต่เมื่อให้รังสีแพทย์ชุดเดิมดูชุดข้อมูลอื่นความแม่นยำกลับลดลงเหลือ 52% เท่านั้น แสดงให้เห็นว่าปัญญาประดิษฐ์ที่จะนำมาใช้งานก็ต้องฝึกกับชุดข้อมูลที่หลากหลายเช่นกัน
ที่มา - Google AI Blog
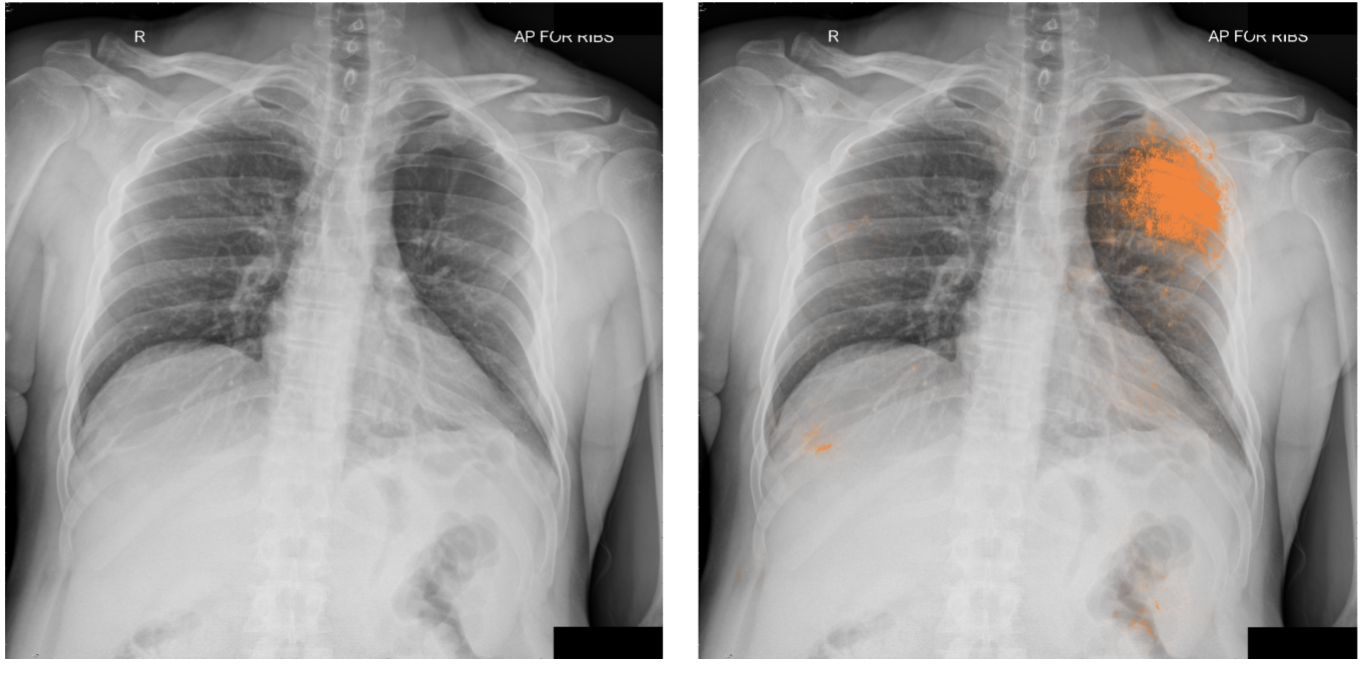
ภาพเอกซเรย์ปอดที่มีภาวะปอดรั่วทางฝั่งซ้าย โดยรังสีแพทย์หลายคนอ่านพลาดเมื่ออ่านภาพเอกซเรย์คนเดียว แต่โมเดลปัญญาประดิษฐ์และกรรมการตรวจสอบภาพยืนยันอาการ
