ทีมวิจัยสแตนฟอร์ดระบุ AI ในกลุ่ม LLM ยังมั่วสูง ควรใช้กับการแพทย์อย่างระมัดระวัง



ทีมวิจัยจากสถาบัน Human-Centered Artificial Intelligence (HAI) ของมหาวิทยาลัยสแตนฟอร์ด รายงานถึงผลทดสอบการใช้งานปัญญาประดิษฐ์ในกลุ่ม LLM ว่าแม้จะมีข่าวว่า LLM สามารถวินิจฉัยโรคได้อย่างน่าทึ่งแต่ก็มีความผิดพลาดสูง ต้องระมัดระวัง
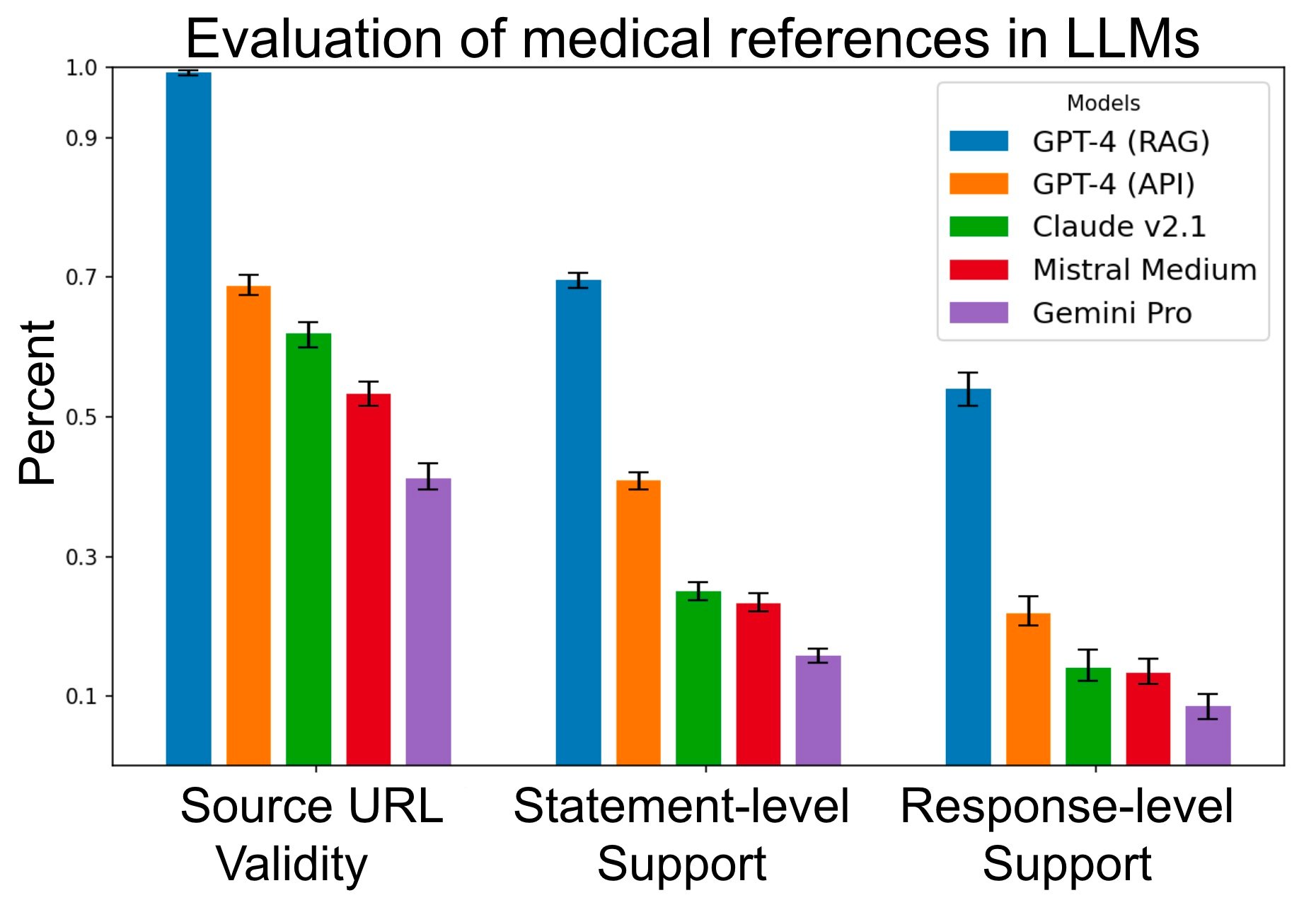
ทีมงานทดสอบการใช้งาน LLM โดยใช้โมเดล 4 ตัว ได้แก่ GPT-4, Claude 2.1, Mistral Medium, และ Gemini Pro เฉพาะ GPT-4 นั้นสร้างแอป retrieval augmented generation (RAG) ครอบอีกชั้นเพื่อทดสอบ โดยวัดว่าเวลาที่ LLM เหล่านี้ตอบคำถามแล้ว สามารถสร้างคำตอบโดยมีการอ้างอิงอย่างถูกต้องหรือไม่
การวัดความถูกต้องมี 3 ระดับ ได้แก่ 1) การวัดว่าที่มาข้อมูลมีจริง ตัวปัญญาประดิษฐ์ไม่ได้สร้าง URL มั่วๆ มาเอง, 2) วัดว่าแต่ละประโยคนั้นมีในที่มาจริง มีแหล่งข้อมูลสนับสนุน, 3) วัดว่าคำตอบโดยรวมมีที่มาสนับสนุนจริงหรือไม่ โดยรวมใช้คำถาม 1,200 คำถาม
ผลทดสอบพบว่า LLM มีแนวโน้มจะสร้างที่มาข้อมูลเองค่อนข้างบ่อย แม้แต่ GPT-4 ก็ยังสร้างที่มา มั่วๆ ถึง 30% ปัญหานี้ลดได้โดยอาศัยการทำ RAG ที่แหล่งที่มาเกือบทั้งหมดมีจริง แต่พอไปดูคำตอบแล้วกลับพบว่าข้อความแต่ละส่วนนั้นไม่ได้มีที่มาสนับสนุนประโยคในคำตอบจำนวนมาก แม้แต่ GPT-4 แบบ RAG ก็ยังมีคำตอบแบบนี้สูงถึง 30%
ทีมวิจัยระบุว่ามีกระแสตื่นเต้นที่ LLM สามารถคำคะแนนทดสอบได้เหนือกว่านักเรียนแพทย์ แต่แพทย์จริงๆ นั้นต้องอาศัยการประเมินหลายด้านกว่าการทำข้อสอบแบบตัวเลือกที่ใช้ทดสอบ LLM มาก
ที่มา - Institute for Human-Centered AI