IBM Storage Scale by G-Able ระบบสตอเรจที่ตอบโจทย์ทุกรูปแบบการใช้งานเพื่อการขยายธุรกิจที่ไม่ติดข้อจำกัด



ธุรกิจในปีที่ผ่านมาอาจจะเรียกได้ว่าเข้าถึงยุคข้อมูลอย่างสมบูรณ์ จากกระแสปัญญาประดิษฐ์ที่เข้ามาอย่างชัดเจนตั้งแต่ปี 2023 ที่ผ่านมา และองค์กรจำนวนมากต้องการปรับตัวเข้าสู่ยุคนี้ให้ทันท่วงที กระบวนการเตรียมข้อมูลเพื่อให้วิเคราะห์ข้อมูลได้รอบด้าน หรือจะเป็นการเตรียมข้อมูลสำหรับปัญญาประดิษฐ์ในองค์กรก็เป็นแนวทางสำคัญสำหรับการมุ่งสู่การพัฒนาระบบไอทีในยุคต่อไป
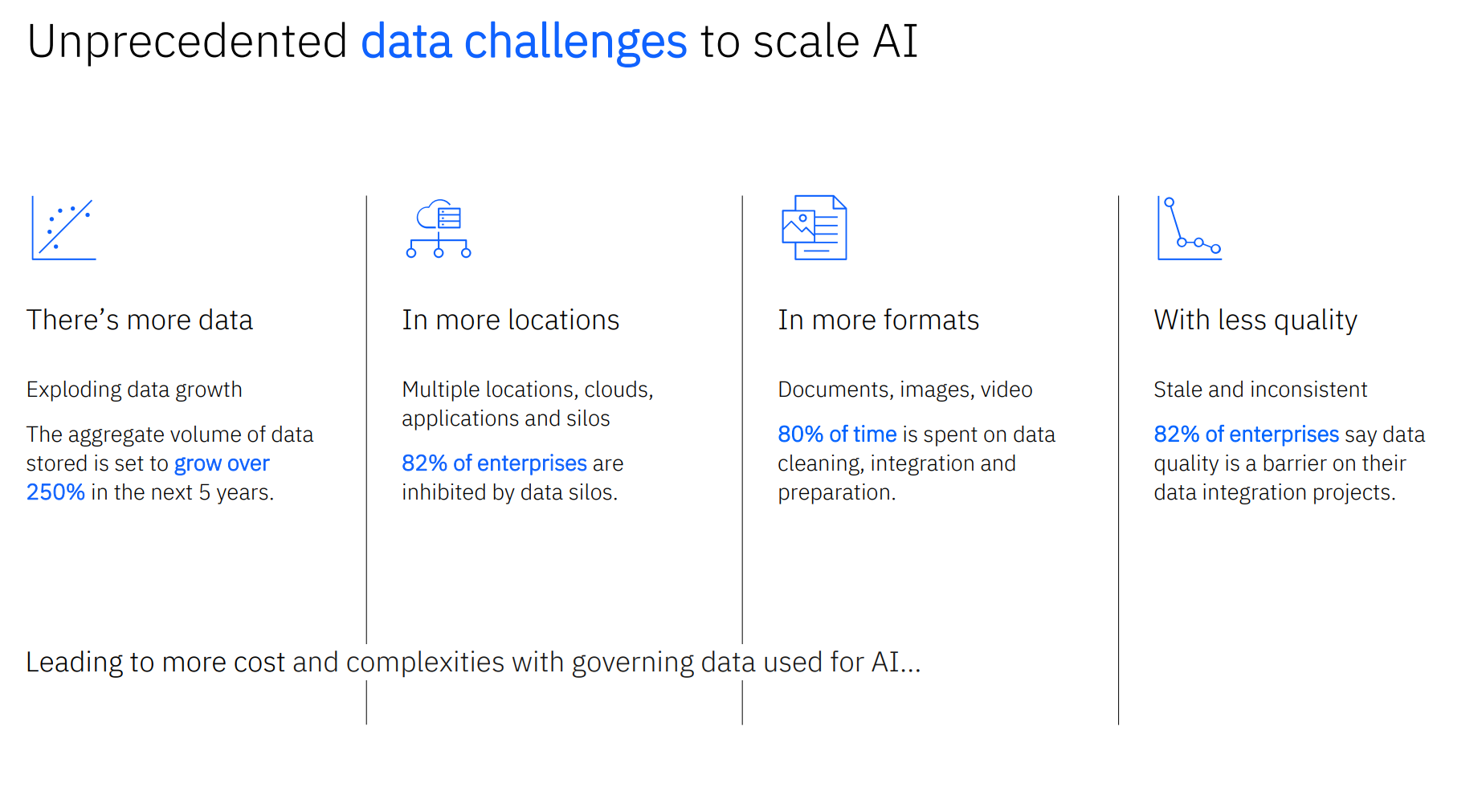
แต่องค์กรหลายแห่งอาจจะต้องพบปัญหากับการเตรียมข้อมูลเหล่านี้ เพราะข้อจำกัดของระบบต่างๆ ที่เก็บข้อมูลหลากหลาย ทั้งรูปแบบที่ชัดเจน (structured) หรือข้อมูลที่ไม่มีรูปแบบ (unstructured) แอปพลิเคชันที่เป็นต้นทางของข้อมูลต้องการการสตอเรจรูปแบบต่างกัน และที่สำคัญคือข้อมูลที่เข้ามามีจำนวนมหาศาลจนระบบสตอเรจรับมือไม่ไหว กลายเป็นคอขวดสำหรับการนำข้อมูลมาใช้งาน แม้ระบบทุกวันนี้อาจจะทำงานได้แต่ระบบเหล่านี้ก็มักแยกส่วนกระจายอยู่ในองค์กร ไม่มีระบบจัดการรวมศูนย์ว่าข้อมูลใดอยู่ตรงไหนหรือมีการจัดการอย่างไร
IBM Storage Scale เป็นโซลูชันที่เข้ามารับมือปัญหาเหล่านี้อย่างครบถ้วน ด้วยการนำเสนอโซลูชันซอฟต์แวร์ที่สามารถรันได้ทั้งบนเซิร์ฟเวอร์ของ IBM เอง, เซิร์ฟเวอร์ที่องค์กรมีอยู่เดิมแล้ว, หรือเซิร์ฟเวอร์บนคลาวด์ที่องค์กรใช้งานอยู่ องค์กรสามารถรวบเอาระบบจัดการข้อมูลทั้งหมดเข้ามาเป็นระบบรวมศูนย์ระบบเดียว ที่รองรับทุกแอปพลิเคชัน ทุกโปรโตคอลที่แอปพลิเคชันยอดนิยมต้องการใช้งาน เช่น การใช้สตอเรจบนคอนเทนเนอร์ในแอปพลิเคชันยุคใหม่, การเชื่อมระบบไฟล์ผ่านโปรโตคอลที่ใช้งานมานานอย่าง NFS หรือ SMB, การใช้สตอเรจผ่าน S3 API ที่ได้รับความนิยมมากขึ้นเรื่อยๆ ไปจนถึงการใช้งานสตอเรจเฉพาะทางสำหรับงาน Analytics หรือ Data Lake ด้วย HDFS เปิดทางเชื่อมต่อ Hadoop เข้าสู่ Storage Scale ได้โดยตรง

ระบบที่รวมศูนย์กลางการจัดการเช่นนี้ ทำให้องค์กรมองเห็นการใช้งานอย่างครบถ้วน สามารถจัดการนโยบายความปลอดภัยได้อย่างเป็นระบบ เช่น การจัดเก็บ log การเข้าถึงข้อมูลต่างๆ จากศูนย์กลาง, การวางนโยบายการเข้ารหัสข้อมูลป้องกันเหตุรั่วไหล, หรือแม้แต่การสั่งให้สตอเรจบางส่วนกลายเป็นข้อมูลอ่านอย่างเดียวไม่สามารถแก้ไขได้ การจัดการนโยบายสามารถสำรองข้อมูลไปยังคลาวด์ต่างๆ ด้วยฟีเจอร์ Transparent Cloud Tiering เลือกโยกข้อมูลขึ้นสู่คลาวด์ได้หลากหลายผู้ให้บริการ
ตัวเซิร์ฟเวอร์ของ Storage Scale รองรับการทำงานขนานกันเต็มรูปแบบ สามารถใช้งานกับเซิร์ฟเวอร์หลายตัวแบบ active-active ได้ทำให้ขยายการใช้งานได้โดยไม่มีคอขวด ไอบีเอ็มเองเคยทดสอบทรูพุตที่ระดับ 2.5TB/s มาแล้ว การจัดการไฟล์รองรับปริมาณไฟล์ระดับพันล้านไฟล์ได้ และปริมาณข้อมูลรวมนั้นไปถึงระดับบ yottabytes (ล้านล้านเทราไบต์) เลยทีเดียว
การใช้งานสตอเรจประสิทธิภาพสูงมาก เป็นฟีเจอร์สำคัญของการใช้งานด้านปัญญาประดิษฐ์ที่ต้องการดึงข้อมูลเข้าสู่ระบบฝึกปัญญาประดิษฐ์ให้เร็วที่สุด Storage Scale รองรับการใช้งานฮาร์ดแวร์ทุกรูปแบบตั้งแต่สตอเรจแฟลชความเร็วสูงไปจนถึงการใช้คลาวด์สตอเรจที่อาจใช้งานเพื่อสำรองข้อมูล ระบบการจัดการ storage tier ทำให้มีพื้นที่เพียงพอสำหรับการใช้งาน พร้อมๆ กับที่แอปพลิเคชันสามารถเข้าถึงข้อมูลได้อย่างรวดเร้ว
Storage Scale เปิดให้เลือกใช้ได้หลากหลายรูปแบบ ทั้งการใช้ซอฟต์แวร์อย่างเดียว, ใช้งานพร้อมกับฮาร์ดแวร์สตอเรจของไอบีเอ็ม, และการใช้งานผ่านบริการคลาวด์ที่รองรับคลาวด์ชั้นนำทั้งหมด
IBM Storage Scale by G-Able โซลูชันครบวงจรตั้งแต่แอปพลิเคชันจนถึงสตอเรจ
G-Able นำเสนอ IBM Storage Scale โดยอาศัยประสบการณ์ในการทำงานด้าน Big Data / Data Lake มาเป็นเวลานาน รวมถึงมีพันธมิตรทั้งบริษัทด้านปัญญาประดิษฐ์ชั้นนำที่ร่วมกับสร้างระบบให้กับลูกค้า การนำเสนอ IBM Storage Scale จึงเป็นการเลือกมาแล้วว่านี่เป็นโซลูชันที่ตอบโจทย์ความต้องการขององค์กรที่ต้องการพัฒนาระบบไอทีให้รองรับข้อมูลขนาดใหญ่อย่างแท้จริง และเมื่อองค์กรเลือกให้ทีมงาน G-Able เข้าไปอิมพลีเมนต์ระบบสตอเรจให้ ก็แน่ใจได้ว่าจะได้รับประสบการณ์ที่ดี การดูแลที่ส่งผลไปยังความสำเร็จขององค์กรที่จะมี Data Lake หรือ AI ที่ทรงพลัง กลายเป็นเครื่องมือสำคัญสำหรับการแข่งกันธุรกิจขององค์กรในยุคต่อไป
สนใจโซลูชัน IBM Storage Scale by G-Able ติดต่อได้ที่ contactcenter@g-able.com หรือศึกษาข้อมูลของ G-Able ได้ที่เว็บไซต์ www.g-able.com