กูเกิลเผยรายละเอียดการรัน Gemini Nano ในแอนดรอยด์, เตรียมเปิดให้แอพอื่นใช้งาน, ใช้โมเดลอื่นได้ด้วย



ในงาน Google I/O 2024 ของใหม่อย่างหนึ่งที่เรียกเสียงฮือฮาในงานคือการโชว์โมเดล Gemini Nano รันในมือถือแอนดรอยด์โดยตรง ทำงานออฟไลน์ แล้วสามารถตรวจสอบการสนทนาที่เป็น scam หลอกหลวงได้ เป็นการโชว์ประโยชน์ของการรันโมเดลในมือถือให้เห็นชัดๆ ว่าทำอะไรได้บ้าง
หลังจากนั้นกูเกิลยังได้ออกวิดีโอเซสชัน Android on-device AI under the hood มาอธิบายรายละเอียดของการรันโมเดลในมือถือแอนดรอยด์เพิ่มเติม มีรายละเอียดดังนี้
ข้อดีของ On-device Gen AI คือประมวลผลในเครื่อง ตอบสนองเร็ว (reduced latency) ทำงานออฟไลน์ได้ และไม่ต้องจ่ายค่าเช่าเครื่องบนคลาวด์เพิ่ม

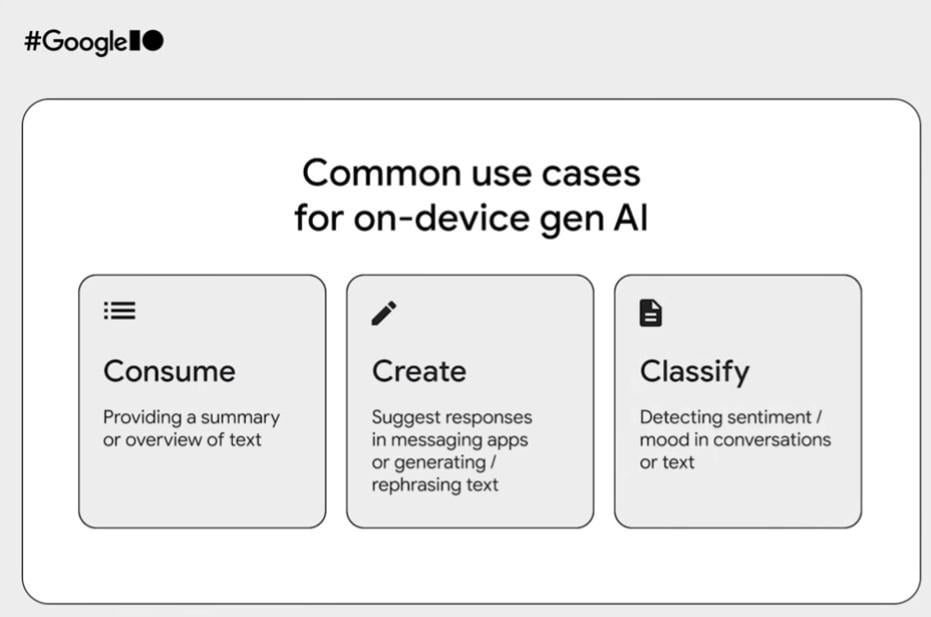
ตัวอย่างการใช้งาน On-device Gen AI ได้แก่ การสรุปเนื้อหา (summary), การแนะนำว่าควรตอบข้อความอย่างไร และการแยกแยะ (classify) อารมณ์ของข้อความ
แต่ก็มีข้อจำกัดเรื่องขนาดของพารามิเตอร์ ขนาดของอินพุต (context window) แปลว่าหากเราต้องการผลลัพธ์ให้ออกมาคุณภาพสูงเหมือนโมเดลบนคลาวด์ จำเป็นต้องปรับแต่ง (fine-tuning) ให้ทำงานเฉพาะด้านได้แม่นยำขึ้น
แนวทางของกูเกิลเปิดให้รันโมเดลในแอนดรอยด์ได้ 2 แบบ ได้แก่ การใช้ Gemini Nano ซึ่งเป็นโมเดลที่กูเกิลเตรียมไว้ให้แล้ว เหมาะกับงานทั่วๆ ไปที่แอพส่วนใหญ่มักใช้งานกัน กับอีกทางคือการนำโมเดลภายนอกมารันผ่าน MediaPipe LLM API เน้นการวิจัยและทดสอบมากกว่า
กรณีของ Gemini Nano ปัจจุบันมีใช้งานแล้วบน Pixel 8 Pro และ Galaxy S24 Series โดยยังจำกัดเฉพาะแอพของกูเกิลบางตัว
ตัวอย่างแอพกูเกิลที่ใช้งานแล้วคือ
- Google Messages มีฟีเจอร์ Magic Compose ช่วยร่างคำตอบแชทให้ผู้ใช้
- Recorder อัดเสียงแล้วสรุปข้อความเสียงว่ามีเนื้อหาอะไรบ้าง ยังรองรับเฉพาะภาษาอังกฤษ
- Gboard แนะนำการตอบแชท แต่เป็นการแนะนำจากตัวคีย์บอร์ดเลย
กูเกิลเริ่มเปิดให้พาร์ทเนอร์บางรายลองใช้ Gemini Nano มาตั้งแต่ปลายปี 2023 และจะเปิดให้นักพัฒนาทั่วไปใช้งานในวงกว้างขึ้นภายในปี 2024
เบื้องหลังการทำงานของ Gemini Nano รันอยู่บน AICore ที่เพิ่งมีใน Android 14 เป็นมาตรฐานในการรัน AI บนแอนดรอยด์
ประเด็นเรื่องขนาดของโมเดลนั้น การรันบน On-Device ใช้โมเดลที่มีขนาดเล็กกว่ามาก (น้อยกว่า 10GB) เทียบกับโมเดลบนคลาวด์ที่ใหญ่กว่า 100GB และปัจจุบันกูเกิลได้ปรับแต่งโมเดลแบบ On-Device ให้เล็กกว่าเดิมมาก ขนาดเหลือแค่ราว 1GB แต่มีความเร็วการทำงานที่ดีขึ้นมากๆ (รองรับอินพุตเยอะกว่า 500 token ต่อวินาที)
เรื่องสำคัญของการรันโมเดล On-Device คือการปรับแต่ง (fine-tuning) ให้โมเดลเก่งขึ้นในงานประเภทที่เราต้องการ กูเกิลใช้เทคนิค Low-Rank Adaptation (LoRA) เข้าช่วย ซึ่งเป็นวิธีที่มีประสิทธิภาพดีกว่าการทำ prompt engineering ที่ปลายทาง แต่นักพัฒนาก็ต้องเตรียมข้อมูลมาเทรนให้พร้อม เพราะข้อมูลไม่ควรใหญ่เกิน 10,000 ชุด และต้องมีความหลากหลายมากพอด้วย ดังนั้นนักพัฒนาควรเทรนข้อมูลหลายๆ แบบแล้วมาดูผลว่าแบบไหนดีที่สุด
ส่วนอีกท่าคือการใช้โมเดลภายนอกอื่นๆ มารันบนแอนดรอยด์ กูเกิลเปิดทางให้รันผ่าน MediaPipe LLM API ซึ่งยังจำกัดเฉพาะโมเดลแบบข้อความ (text-to-text) เท่านั้น
ตัวอย่างโมเดลที่นำมาโชว์คือ Falcon-1B ของสถาบันวิจัย Technology Innovation Institute (TII) ในอาหรับเอมิเรตส์, Phi-2 ของไมโครซอฟท์, Stable LM 3B ของ Stability.ai และ Gemma ของกูเกิลเอง
ที่มา - 9to5google
