กูเกิลเริ่มใช้ระบบดัชนีเว็บตัวใหม่ Caffeine แล้ว



เมื่อปีก่อนผมเคยเขียนเกี่ยวกับ Caffeine ระบบดัชนีเว็บ (web index) รุ่นใหม่ของกูเกิลไปบ้าง (ข่าวเก่า กูเกิลเปิดให้ทดสอบ Caffeine ระบบดัชนีเว็บรุ่นใหม่)
ตอนนี้ Caffeine เสร็จสมบูรณ์แล้ว และกูเกิลก็นำมันมาใช้งานจริงแล้วในศูนย์ข้อมูลทุกแห่ง และกูเกิลทุกภาษา
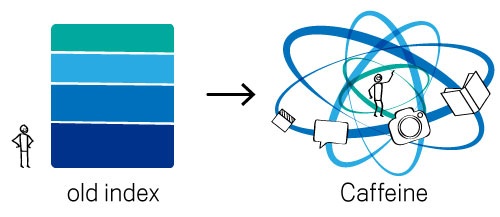
กูเกิลบอกว่าระบบดัชนีแบบเก่า เก็บข้อมูลเว็บเป็นเลเยอร์ที่มีความถี่ในการอัพเดตไม่เท่ากัน (ดูภาพประกอบ) ส่วนของเลเยอร์หลักมีขนาดใหญ่มาก และการอัพเดตข้อมูลทั้งหมดของเลเยอร์หลักต้องใช้เวลาหลายสัปดาห์ ทำให้ข้อมูลในดัชนีของกูเกิลเก่าเกินไป เริ่มล้าสมัยสำหรับความต้องการของผู้ใช้ยุคนี้แล้ว
แต่ Caffeine จะแยกดัชนีเป็นส่วนๆ เป็นอิสระต่อกัน เมื่อส่ง crawler วิ่งไปดูดข้อมูลแล้ว สามารถอัพเดตลงในดัชนีได้ทันที ทำให้ข้อมูลในผลการค้นหาทันสมัย แถมรองรับข้อมูลแบบเรียลไทม์อย่าง Twitter/Facebook ได้ กูเกิลบอกว่า Caffeine มีขนาดข้อมูลประมาณ 100 PB (เพตะไบต์) ต่อหนึ่งฐานข้อมูล
ที่มา - Google Blog, Search Engine Land