DeepMind โชว์ผลงานใช้ AI สร้างคลื่นเสียงเลียนแบบเสียงพูดของมนุษย์-เสียงดนตรีได้แล้ว



ทีมปัญญาประดิษฐ์ DeepMind ของกูเกิล (ผู้สร้าง AlphaGo) โชว์ผลงานใหม่ WaveNet โมเดลปัญญาประดิษฐ์ที่สร้างเสียงสังเคราะห์ได้จากรูปแบบคลื่นเสียงของมนุษย์ สามารถใช้สร้างได้ทั้งเสียงพูด (speech) และเสียงดนตรี (music) จากการเรียนรู้ผ่าน deep learning
เป้าหมายหลักของ WaveNet ต้องการนำมาสร้างเสียงพูดสังเคราะห์ (text-to-speech หรือ TTS) ซึ่งปัจจุบัน ระบบสังเคราะห์เสียงพูด TTS ส่วนใหญ่เก็บเสียงพูดเป็นคำสั้นๆ แล้วนำเสียงมาต่อกันเป็นประโยค (มีชื่อเรียกว่า concatenative TTS) ซึ่งมีข้อเสียคือดัดแปลงเสียงได้ยาก เพราะต้องอัดเสียงใหม่ทั้งหมด
ในแวดวงจึงพัฒนาระบบเสียงสังเคราะห์ที่เรียกว่า parametric TTS ที่เปลี่ยนคุณสมบัติของเสียง (เช่น เพศหรืออายุของคนพูด) ได้จากพารามีเตอร์ที่ป้อนให้ แต่ข้อจำกัดของโมเดลนี้คือเสียงที่สังเคราะห์ได้ยังไม่เป็นธรรมชาติ (เมื่อเทียบกับ concatenative TTS)
WaveNet นำแนวคิดเรื่องการสร้างคลื่นเสียง (raw waveform) จาก AI เข้ามาปรับปรุง parametric TTS ให้ได้เสียงที่เป็นธรรมชาติมากขึ้น วิธีการคือเทรน AI ให้รู้จักรูปแบบของคลื่นเสียงโดยตรง ลักษณะเดียวกับ AI ที่ใช้สร้างรูปภาพที่ซับซ้อนขึ้นมาได้ด้วยโมเดล convolution neural network แบบหลายเลเยอร์
ขั้นตอนการทำงานของ WaveNet คืออัดเสียงพูดของมนุษย์ แล้วเทรน AI ให้เรียนรู้คลื่นเสียงแต่ละแบบไปเรื่อยๆ หลังจากนั้น AI จะสามารถสร้างคลื่นเสียงลักษณะคล้ายๆ กัน (แต่อาจฟังไม่รู้เรื่องเป็นคำๆ) ขึ้นมาได้ ซึ่งทีมงาน DeepMind ต้องนำไปรวมกับข้อความ (text) เพื่อแปลงเป็นเสียงพูดที่ฟังแล้วมีความหมายจริงๆ (ทีมงาน WaveNet ลองเอาไปสร้างเสียงดนตรีได้ด้วย โดยเทรนเสียงเปียโนให้ ผลก็ออกมาใช้ได้ เพราะไม่ต้องมีตัว text มาประกอบ)
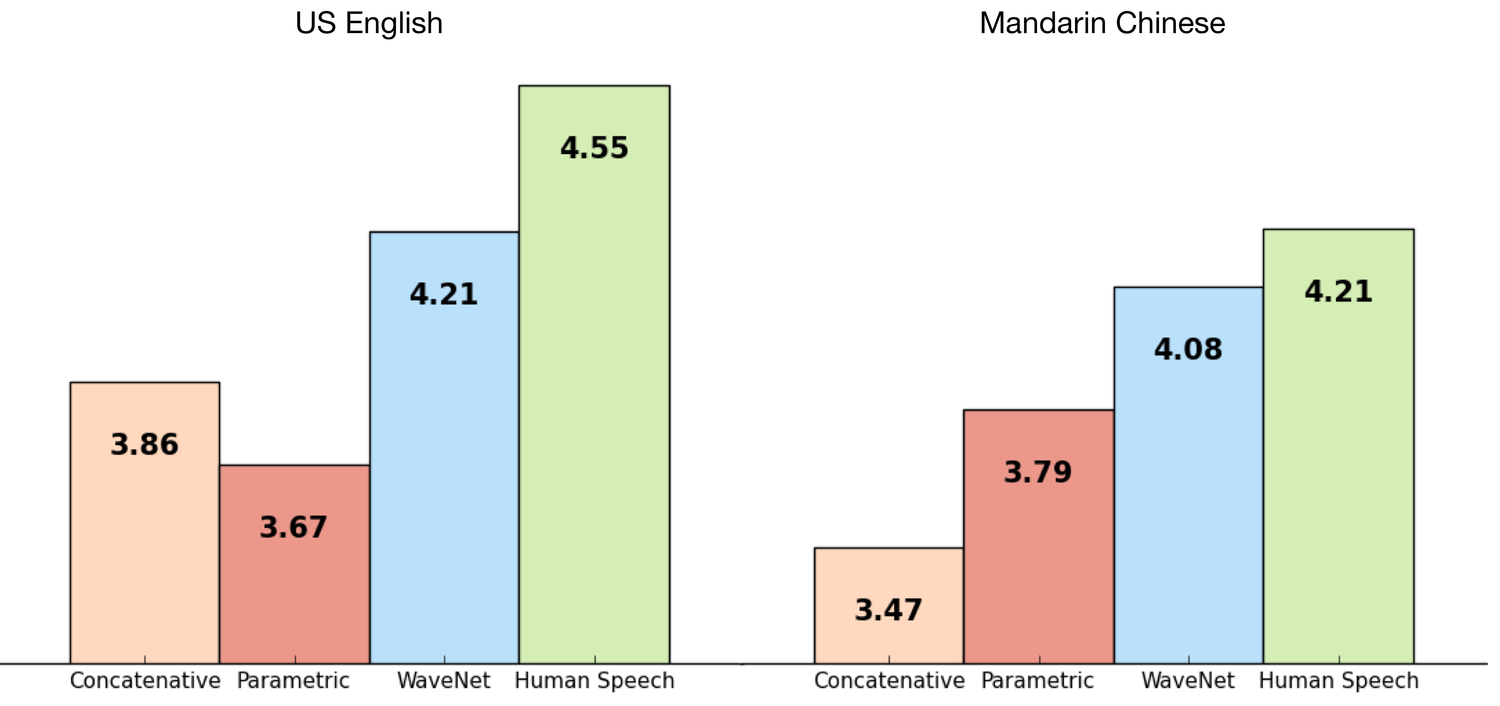
DeepMind ลองทดสอบ WaveNet (สีฟ้าในกราฟ) เทียบกับเสียงพูดจริงของมนุษย์ (สีเขียวในกราฟ) พบว่ามีความใกล้เคียงมากขึ้น เมื่อเทียบกับเสียงที่ได้จาก Google TTS ตัวที่ใช้ใน Android ปัจจุบัน (สีชมพูและสีแดง) ในภาพรวมแล้วประสิทธิภาพของ WaveNet ดีขึ้นกว่า Google TTS ถึง 50%
ใครสนใจลองฟังเสียงจาก WaveNet ก็เข้าไปทดสอบกันได้ตามลิงก์
ที่มา - DeepMind