กูเกิลเปิดโมเดลการฝึกปัญญาประดิษฐ์แบบไม่เห็นข้อมูล เริ่มใช้งานกับ Gboard



ส่วนสำคัญของการฝึกระบบปัญญาประดิษฐ์คือซอฟต์แวร์ฝึกจะต้องเห็นข้อมูลจำนวนมาก แต่สำหรับข้อมูลส่วนตัวเช่นคีย์บอร์ด การส่งข้อมูลกลับไปยังเซิร์ฟเวอร์เพื่อฝึกปัญญาประดิษฐ์ให้แนะนำคำได้ดียิ่งขึ้น จะเสี่ยงต่อการละเมิดความเป็นส่วนตัวอย่างมาก
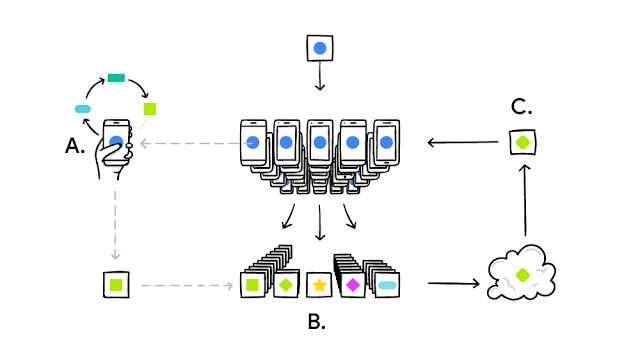
ตอนนี้กูเกิลก็เสนอทางออกใหม่ที่ไม่ต้องส่งข้อมูลกลับไปยังเซิร์ฟเวอร์โดยตรง แต่ยังปรับปรุงปัญญาประดิษฐ์จากการใช้งานได้ เรียกว่า Federated Learning
ในระบบ Federated Learning ผู้ใช้ทุกคนจะได้รับปัญญาประดิษฐ์เริ่มต้นมาเหมือนๆ กัน จากนั้นเมื่อผู้ใช้เริ่มแนะนำข้อมูลใหม่ๆ เข้าไป ระบบปัญญาประดิษฐ์ก็จะปรับปรุงตัวเองบนเครื่องผู้ใช้ ทำให้เมื่อใช้งานไประยะหนึ่งแล้ว ปัญญาประดิษฐ์บนเครื่องผู้ใช้แต่ละคนจะมีพฤติกรรมต่างกันออกไป
หลังจากนั้นซอฟต์แวร์จะส่งข้อมูลที่เปลี่ยนแปลงในเครื่องกลับไปยังเซิร์ฟเวอร์ ที่จะรวมเอาความแตกต่างของปัญญาประดิษฐ์ในแต่ละเครื่องเข้าด้วยกัน ด้วยอัลกอริทึม Federated Averaging เพื่อปรับปรุงพฤติกรรมของปัญญาประดิษฐ์ในรอบต่อไป
กระบวนการนี้ต้องคิดถึงปริมาณข้อมูลที่ต้องส่งกลับเซิร์ฟเวอร์ให้มีขนาดเล็ก โดยกูเกิลออกแบบการอัพเดตให้มีข้อมูลเล็กลงถึงร้อยเท่า ขณะที่ในแง่ความเป็นส่วนตัวก็ได้ออกแบบโปรโตคอล Secure Aggregation ที่จะไม่สามารถถอดความเปลี่ยนแปลงของปัญญาประดิษฐ์ออกมาศึกษาพฤติกรรม (ซึ่งอาจจะทำให้รู้ว่าผู้ใช้คนนั้นๆ มีพฤติกรรมแบบใดเป็นพิเศษ เช่นชอบข้อความบางอย่าง ร้านอาหารบางชนิด ฯลฯ) แต่ต้องมีผู้ใช้ตั้งแต่ 100 ถึง 1000 มาเกลี่ยความเปลี่ยนแปลงออกไปเสียก่อน จึงสามารถดูความเปลี่ยนแปลงของปัญญาประดิษฐ์ได้
ระบบเช่นนี้ใช้งานแล้วกับ Gboard ที่จะฝึกปัญญาประดิษฐ์ในตัวเพิ่มเติมเมื่อผู้ใช้ไม่ได้ใช้งานเครื่องและเสียบสายชาร์จอยู่
กูเกิลระบุว่าเทคโนโลยีเช่นนี้ไม่สามารถใช้งานกับงานทุกประเภท เช่น งาน label ข้อมูลอย่างการระบุพันธุ์สุนัขหรือการตรวจจับสแปม ต้องอาศัยข้อมูลที่บรรยายไว้อย่างแม่นยำอยู่บนเซิร์ฟเวอร์
ที่มา - Google Research