กูเกิลเผยอัลกอริทึม Gboard นำ Machine Learning ช่วยสร้างคีย์บอร์ดที่แม่นยำ



เดือนที่แล้ว กูเกิลเพิ่งเพิ่มความสามารถให้ Gboard for Android ไปชุดใหญ่ ทั้งการรองรับภาษาใหม่ๆ (ส่วนใหญ่เป็นภาษาในประเทศอินเดีย) และการพิมพ์ตัวอักษรภาษาฮินดีด้วยแป้นภาษาอังกฤษ (Gboard จะเดาคำให้เราเอง)
ล่าสุดกูเกิลเผยแพร่รายละเอียดของอัลกอริทึมเบื้องหลัง Gboard เวอร์ชันใหม่ ว่านำ machine learning มาช่วยปรับปรุง Gboard ได้อย่างไร
เทคนิคของกูเกิลแบ่งออกเป็น 2 ส่วน ได้แก่ การเรียนรู้การลากนิ้ว (glide typing) และการเรียนรู้เรื่องการเดาคำต่อไปที่ผู้ใช้จะพิมพ์
Neural Spatial Models
ปัญหาของคีย์บอร์ดแบบลากนิ้ว (glide หรือที่เราเรียกกันว่า swipe) คือคำบางคำอาจลากนิ้วแบบเดียวกัน ส่งผลให้ยากที่จะเดาว่าผู้ใช้ต้องการพิมพ์คำว่าอะไรกันแน่ อย่างในภาพตัวอย่างเป็นการลากคำว่า value และ vampire ที่ใกล้เคียงกันมาก
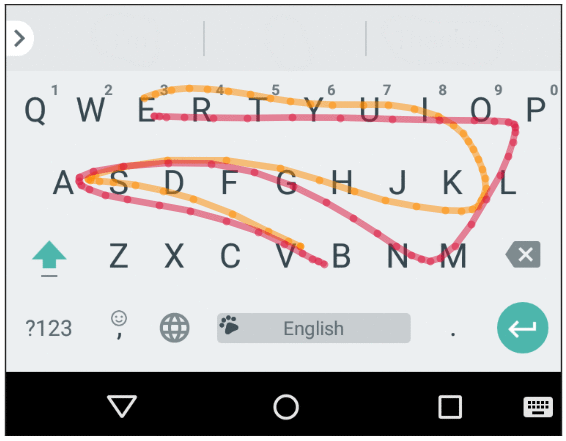
ที่ผ่านมา Gboard ใช้โมเดล Gaussian พิจารณาความน่าจะเป็นจากปัจจัยต่างๆ ซึ่งเป็นโมเดลที่ง่ายแต่ไม่มีประสิทธิภาพมากนัก ช่วงหลังกูเกิลจึงปรับมาใช้โมเดลที่เรียกว่า long short-term memory (LSTM) โดยเทรนด้วยเกณฑ์แบบ connectionist temporal classification (CTC) บนสถาปัตยกรรม TensorFlow
เทคนิคนี้กูเกิลพัฒนามาจากการเทรนแยกแยะเสียงใน Google Voice Search ที่มีความคล้ายคลึงกัน กูเกิลใช้เวลาพัฒนาเทคนิคนี้อยู่ปีกว่าจนเป็นที่พอใจ ผลคือโมเดลทำงานได้เร็วขึ้นกว่าเดิม 6 เท่าในขนาดที่เล็กกว่าเดิม 10 เท่า เดาคำผิดน้อยลง 10% และเสนอ autocorrect ผิดน้อยลง 15%
Finite-State Transducers
นอกจากการวิเคราะห์สถิติการลากนิ้วของผู้ใช้ กูเกิลยังต้องเดาคำจากความเป็นไปได้ในเชิงไวยากรณ์ของภาษา ว่าพิมพ์ตัวอักษรตัวนี้แล้ว ตัวถัดไปน่าจะเป็นตัวไหน
กูเกิลนำเทคนิค Finite-State Transducers (FST) มาใช้งาน การใช้เทคนิคนี้ช่วยให้กูเกิลสามารถสร้างฟีเจอร์ transliteration หรือการพิมพ์ข้อความในภาษาหนึ่งด้วยตัวอักษรอีกภาษาหนึ่งได้ (เหมือนกับ Pinyin ของภาษาจีน ที่พิมพ์ xièxiè ได้ผลออกมาเป็น “谢谢”)
กรณีของ Pinyin มีกฎเกณฑ์ตายตัวว่าตัวจีนแบบนี้ต้องพิมพ์ตัวละตินอย่างไร แต่ในหลายภาษา เช่น ฮินดี (รวมถึงไทย) ไม่มีกฎเกณฑ์ตายตัว ส่งผลให้คีย์บอร์ดต้องเดาเองว่าผู้ใช้ต้องการพิมพ์อะไรบ้าง กูเกิลจึงใช้ machine learning ช่วยสร้างโมเดลของการพิมพ์ภาษาเหล่านี้ขึ้นมา และสามารถสร้างได้ถึง 57 โมเดลในเวลาเพียงไม่กี่เดือน ซึ่งไม่สามารถทำได้ถ้าเป็นแรงงานมนุษย์
ที่มา - Google Research